K 均值算法
聚类问题 Clustering¶
针对监督式学习,输入数据为 (x, y) ,目标是找出分类边界,即对新的数据进行分类。而无监督式学习只给出一组数据集 ${x_1, x_2, … , x_m}$ ,目标是去找出这组数据的模式特征,比如哪些数据是一种类型的,哪些数据是另外一种类型的。典型的无监督式学习包括市场细分,通过分析用户数据,来把一个产品的市场进行细分,找出细分人群。另外一个是社交网络分析,分析社交网络中的参与人员的不同特点,根据特点区分出不同群体。这些都是无监督式学习里的聚类 (Clustering) 问题。
K 均值算法¶
K 均值算法算法就是一种解决聚类问题的算法,它包含两个步骤:
- 给聚类中心分配点:计算所有的训练样例,把他分配到距离某个聚类中心最短的的那聚类里。
- 移动聚类中心:新的聚类中心移动到这个聚类所有的点的平均值处。
一直重复做上面的动作,直到聚类中心不再移动为止。这个时候我们就探索出了数据集的结构了。可以通过一个动画来直观地看一下 K 均值算法聚类的过程:

用数学的方法来描述 K 均值算法如下:
算法有两个输入信息。一是 K 表示选取的聚类个数;二是训练数据集 ${x^{(1)}, x^{(2)}, … , x^{(m)}}$。
- 随机选择 K 个聚类中心 $u_1, u_2, … , u_k$。
- 从 1 - m 遍历所有的数据集,计算 $x^{(i)}$ 分别到 $u_1, u_2, … , u_k$ 的距离,记录距离最短的聚类中心点。然后把 $x^{(i)}$ 这个点分配给这个聚类。令 $c^{(i)} = j$ 其中 $u_j$ 就是与 $x^{(i)}$ 距离最短的聚类中心点。计算距离时,一般使用 $| x^{(i)} - u_j |^2$ 来计算。
- 从 1 - K 遍历所有的聚类中心,移动聚类中心的新位置到这个聚类的均值处。即 $u_j = \frac{1}{c} \left( \sum_{d=1}^c \right)$ ,其中 c 表示分配给这个聚类的训练样例点的个数。如果特殊情况下,没有点分配给这个聚类中心,那么说明这个聚类中心就不应该存在,直接删除掉这个聚类中心,最后聚类的个数变成 K - 1 个。
- 重复步骤 2 ,直到聚类中心不再移动为止。
K 均值算法成本函数¶
$$ J = \frac{1}{m} \sum_{i=1}^m | x^{(i)} - u_{c^{(i)}} |^2 $$
其中, $c^{(i)}$ 是训练样例 $x^{(i)}$ 分配的聚类序号;$u_{c^{(i)}}$ 是 $x^{(i)}$ 所属的聚类的中心点。K 均值算法的成本函数的物理意义,就是训练样例到其所属的聚类中心点的距离的平均值。
随机初始化聚类中心点¶
假设 K 是聚类的个数,m 是训练样本的个数,那么必定有 $K < m$。在随机初始化时,随机从 m 个训练数据集里选择 K 个样本来作为聚类中心点。这是正式推荐的随机初始化聚类中心的做法。
在实际解决问题时,最终的聚类结果会和随机初始化的聚类中心点有关。即不同的随机初始化的聚类中心点可能得到不同的最终聚类结果。因为成本函数可能会收敛在一个局部最优解,而不是全局最优解上。一个解决方法是多做几次随机初始化的动作,然后训练出不同的取类中心点以及聚类节点分配方案。然后用这些值算出成本函数,最终选择那个成本最小的。
比如,假设我们做 100 次运算,步骤如下:
- 随机选择 K 个聚类中心点
- 运行 K 均值算法,算出 $c^{(1)}, c^{(2)}, … , c^{(m)}$ 和 $u_1, u_2, … , u_k$
- 使用 $c^{(1)}, c^{(2)}, … , c^{(m)}$ 和 $u_1, u_2, … , u_k$ 算出最终的成本值
- 记录最小的成本值,然后跳回步骤 1,直到达到最大运算次数
这样我们可以适当加大运算次数,从而求出全局最优解。
选择聚类的个数¶
怎么样选择合适的聚类个数呢?实际上聚类个数和业务有紧密的关联,比如我们要对 T-Shirt 大小进行聚类分析,我们是分成 3 个尺寸好呢还是分成 5 个尺寸好?这个更多的是个业务问题而非技术问题。3 个尺寸可以给生产和销售带来便利,但客户体验可能不好。5 个尺寸客户体验好了,但可能会给生产和库存造成不便。
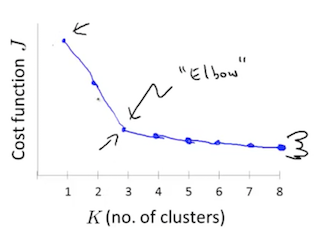
从技术角度来讲,也是有一些方法可以来做一些判断的。我们可以把聚类个数作为横坐标,成本函数作为纵坐标,这样把成本和聚类个数的数据画出来。如上图所示。大体的趋势是随着 K 值越来越大,成本越来越低。我们找出一个拐点,即在这个拐点之前成本下降比较快,在这个拐点之后,成本下降比较慢,那么很可能这个拐点所在的 K 值就是我们要寻求的最优解。
当然,这个技术方法并不总是有效,我们很可能会得到一个没有拐点的曲线,这样的话,就必须和业务逻辑结合以便选择合适的聚类个数。