逻辑回归算法
分类问题及其表现形式¶
为什么需要逻辑回归算法¶
比如要对一个图片进行分类,判断图片里是否包含汽车。包含汽车的预测值为 1 。不包含汽车的预测值为 0 。这种分类问题的值是离散的,如果用 linear regresstion 来作为分类问题的预测函数是不合理的。因为预测出来的数值可能远小于 0 或远大于 1。我们需要找出一个预测函数模型,使其值的输出在 [0, 1] 之间。然后我们选择一个基准值,比如 0.5 ,如果预测值算出来大于 0.5 就认为其预测值为 1,反之则其预测值为 0.
逻辑回归算法的预测函数¶
我们选择 $g(z) = \frac{1}{1 + e^{-z}}$ 来作为我们的预测函数。这个函数称为 Sigmoid Function 。它的图形如下:

从图中可以看出来,当 $z > 0$ 时,$g(z) > 0.5$ 。当 z 越来越大时,$g(z)$ 接无限接近于 1。当 $z < 0$ 时,$g(z) < 0.5$ 。当 z 越来越小时,$g(z)$ 接无限接近于 0。这正是我们想要的针对二元分类算法的预测函数。
结合我们的线性回归函数的预测函数 $h_\theta(x) = \theta^T x$,则我们的逻辑回归模型的预测函数如下:
$$ h_\theta(x) = g(\theta^T x) = \frac{1}{1 + e^{-\theta^T x}} $$
解读逻辑回归预测函数的输出值
$h_\theta(x)$ 表示针对输入值 $x$ 以及参数 $\theta$ 的前提条件下,$y=1$ 的概率。用概率论的公式可以写成:
$$ h_\theta(x) = P(y=1 \vert x; \theta) $$
上面的概率公式可以读成:在输入 $x$ 及参数 $\theta$ 条件下 $y=1$ 的概率。由概率论的知识可以推导出,
$$ P(y=1 \vert x; \theta) + P(y=0 \vert x; \theta) = 1 $$
判定边界 Decision Boundary¶
从逻辑回归公式说起
逻辑回归预测函数由下面两个公式给出的:
$$ h_\theta(x) = g(\theta^T x) $$
$$ g(z) = \frac{1}{1 + e^{-z}} $$
假定 $y=1$ 的判定条件是 $h_\theta(x) \geq 0.5$,$y=0$ 的判定条件是 $h_\theta(x) < 0.5$,则我们可以推导出 $y=1$ 的判定条件就是 $\theta^T x \geq 0$,$y=0$ 的判定条件就是 $\theta^T x < 0$。所以,$\theta^T x = 0$ 即是我们的判定边界。
判定边界
假定我们有两个变量 $x_1, x_2$,其逻辑回归预测函数是 $h_\theta(x) = g(\theta_0 + \theta_1 x_1 + \theta_2 x_2)$。假设我们给定参数
$$ \theta = \begin{bmatrix} -3 \\ 1 \\ 1 \end{bmatrix} $$
那么我们可以得到判定边界 $-3 + x_1 + x_2 = 0$,即 $x_1 + x_2 = 3$,如果以 $x_1$ 为横坐标,$x_2$ 为纵坐标,这个函数画出来就是一个通过 (0, 3) 和 (3, 0) 两个点的斜线。这条线就是我们的判定边界。
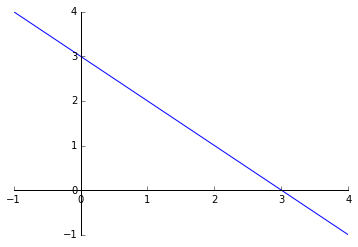
直线左下角为 $y=0$ ,直线右上解为 $y=1$ 。横坐标为 $x_1$,纵坐标为 $x_2$ 。
非线性判定边界
如果预测函数是多项式 $h_\theta(x) = g(\theta_0 + \theta_1 x_1 + \theta_2 x_2 + \theta_3 x_1^2 + \theta_4 x_2^2)$,且给定
$$ \theta = \begin{bmatrix} -1 \\ 0 \\ 0 \\ 1 \\ 1 \end{bmatrix} $$
则可以得到判定边界函数
$$ x_1^2 + x_2^2 = 1 $$
还是以 $x_1$ 为横坐标,$x_2$ 为纵坐标,则这是一个半径为 1 的圆。圆内部是 $y=0$ ,圆外部是 $y=1$。
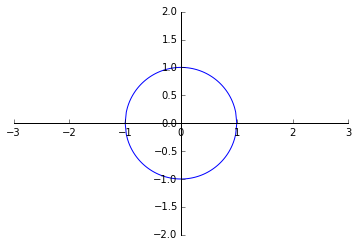
这是二阶多项式的情况,更一般的多阶多项式可以表达出更复杂的判定边界。
逻辑回归的成本函数¶
线性回归的成本函数是 $J(\theta) = \frac{1}{m} \sum_{i=1}^m \frac{1}{2} \left (h_\theta(x^{(i)}) - y^{(i)} \right)^2 $,如果我们按照线性回归的成本函数来计算逻辑回归的成本函数,那么我们最终会很可能会得到一个非凸函数 (non-convex function),这样我们就无法通过梯度下降算法算出成本函数的最低值。
为了让成本函数是个凸函数 (convex function),以便容易求出成本函数的最小值,我们定义逻辑回归的成本函数如下:
$$ Cost(h_\theta(x), y) = \begin{cases} -log(h_\theta(x)), & \text{if $y$ = 1} \\ -log(1 - h_\theta(x)), & \text{if $y$ = 0} \\ \end{cases} $$
成本函数的解读 如果 $y = 1, h_\theta(x) = 1$,那么成本为 $Cost = 0$;如果 $y = 1, h_\theta(x) \rightarrow 0$,那么成本将是无穷大 $Cost \rightarrow \infty$。 如果 $y = 0, h_\theta(x) = 0$,那么成本为 $Cost = 0$;如果 $y = 0, h_\theta(x) \rightarrow 1$,那么成本将是无穷大 $Cost \rightarrow \infty$。
逻辑回归成本函数定义¶
由于 $y \in [0, 1]$ 的离散值,可以把两个成本函数合并起来:
$$ J(\theta) = -\frac{1}{m} \left[ \sum_{i=1}^m y^{(i)} log(h_\theta(x^{(i)})) + (1 - y^{(i)}) log(1 - h_\theta(x^{(i)})) \right] $$
把 $y = 0, y = 1$ 两种情况代入上式,很容易可以验证成本函数合并的等价性。
梯度下降公式¶
我们依然使用梯度下降公式来对模型进行求解。根据梯度下降算法的定义,我们使用下面的公式来进行参数迭代:
$$ \theta_j := \theta_j - \alpha \dfrac{\partial}{\partial \theta_j}J(\theta) $$
这里的关键是求解成本函数的偏导数。在这之前,我们先求出 Sigmoid 函数的偏导数,以便后面可以利用上:
$$ \begin{align} \sigma(x)’ &= \left(\frac{1}{1+e^{-x}}\right)’ = \frac{-(1+e^{-x})’}{(1+e^{-x})^2} = \frac{-1’-(e^{-x})’}{(1+e^{-x})^2} \newline &= \frac{0-(-x)’(e^{-x})}{(1+e^{-x})^2} = \frac{-(-1)(e^{-x})}{(1+e^{-x})^2} = \frac{e^{-x}}{(1+e^{-x})^2} \newline &= \left(\frac{1}{1+e^{-x}}\right)\left(\frac{e^{-x}}{1+e^{-x}}\right) = \sigma(x)\left(\frac{+1-1 + e^{-x}}{1+e^{-x}}\right) \newline &= \sigma(x)\left(\frac{1 + e^{-x}}{1+e^{-x}} - \frac{1}{1+e^{-x}}\right) \newline &= \sigma(x)(1 - \sigma(x)) \end{align} $$
推导出来的这个公式将在下面用上,现在我们可以来计算成本函数的偏导数了:
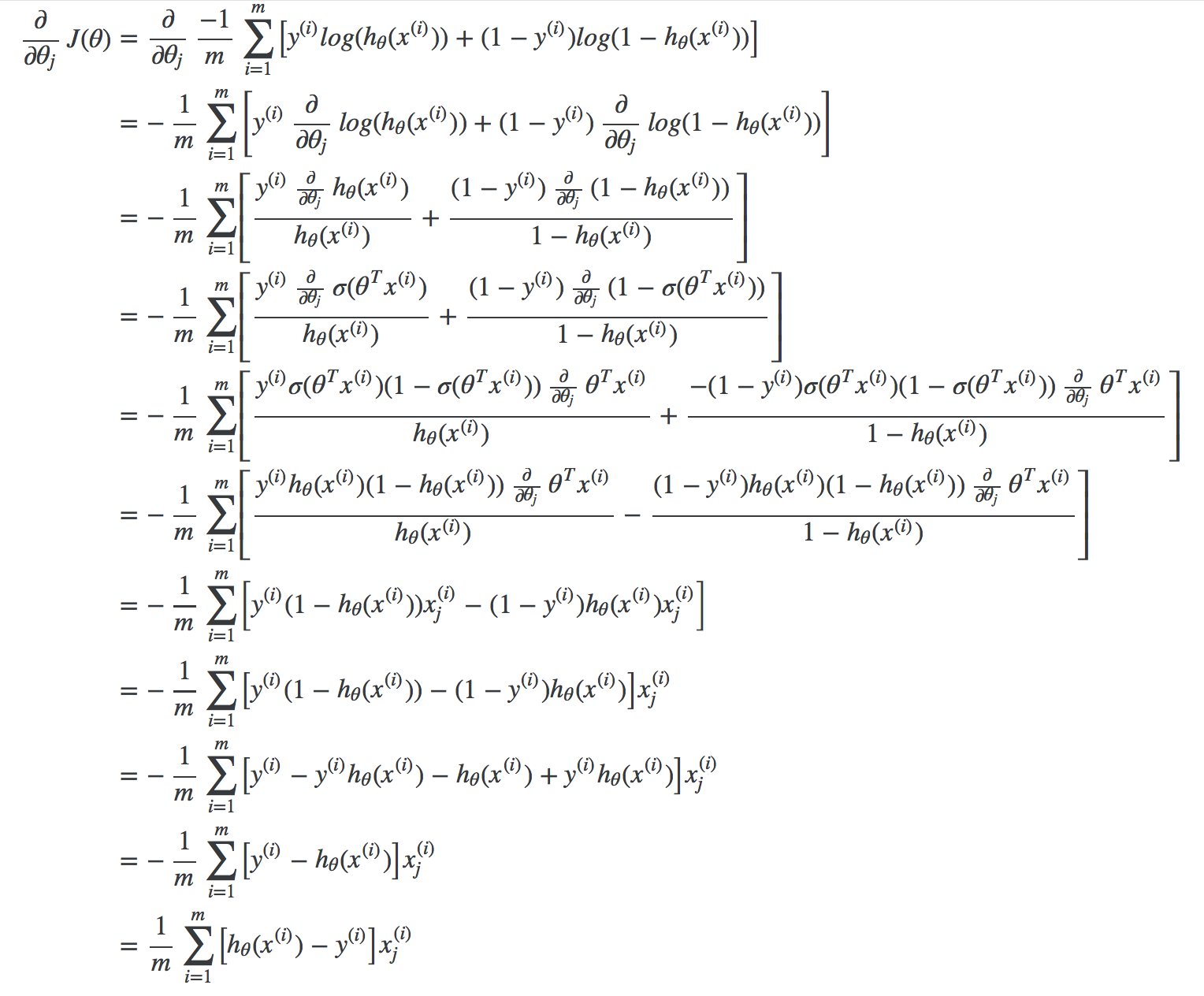
最终得到梯度下降算法进行参数迭代的公式如下:
$$ \theta_j = \theta_j - \alpha \frac{1}{m} \sum_{i=1}^m \left( h_\theta(x^{(i)}) - y^{(i)} \right) x_j^{(i)} $$
这个公式的形式和线性回归算法的参数迭代公式是一样的。当然,由于这里 $h_\theta(x) = \frac{1}{1 + e^{-\theta^T x}}$,而线性回归算法里 $h_\theta(x) = \theta^T x$。所以,两者的形式一样,但数值计算完全不同。
算法优化¶
梯度下降算法的效率是比较低,优化的梯度下降算法有 Conjugate Gradient, BFGS, L-BFGS 等。这些算法比较复杂,实现这些算法是数值计算专家的工作,一般工程人员只需要大概知道这些算法是怎么优化的以及怎么使用这些算法即可。
octave 里提供了 fminunc 函数,可以查阅文档来学习函数用法,从而学会使用优化过的梯度下降算法,以提高计算效率。
多元分类算法¶
除了二元分类算法外,还有多元分类问题,比如需要给邮件打标签,则可能有多个标签需要考虑。这个时候需要使用 one-vs-all (one-vs-rest) 的方法。即把要分类的一种类别和其他所有类别区分开来的,这样就把多元分类问题转化为二元分类问题,这样就可以使用上文总结的所有二元分类问题的算法。
针对 $y = i$,求解针对 i 的预测函数 $h_\theta^{(i)}(x)$。如果有 n 个类别,则需要求解 n 个预测函数。