神经网络(一)
动机¶
为什么我们需要神经网络?
对非线性分类问题,当特征的个数很大的时候,计算量将会非常大。比如对有 100 个特征($x_1, x_2, \cdots, x_100$)的问题,如果我们只算二阶多项多项式,我们将得到大概 5000 个特征 ($O(n^2)$)。而如果按照三阶多项式来模拟,将得到将近 300,000 个特征 ($O(n^3)$)。再比如,针对一个 100 x 100 分辨率的图片,我们假设每个象素点只用黑白来表示,那么将得到 100,000 个特征值。这个时候如果用二阶多项式来拟合,我们将得到 50,000,000,000 个特征值组合。这是非常巨大的计算量。
显然,用线性回归和逻辑回归来解决这类问题是不现实的。
神经网络模型¶
神经网络模型是依照大脑的神经网络的结构建模的。即多个神经元构成一个层,这些神经元是输入,层的目标值为输出。一个神经网络包含多个层。神经元是神经网络中的运算单位。
神经元¶
神经元是神经网络中的最小运算单位,多个神经元构成一个层。神经网络依然使用逻辑回归算法里介绍的 Sigmoid Function 作为基本模型。
$$ g(z) = \frac{1}{1 + e^{-z}} \\ z = \theta^T x \\ h_\theta(x) = \frac{1}{1 + e^{-\theta^T x}} $$
其中,$x$ 称作神经元的输入 (input wires or Dendrite),是个列向量 $[x_1, x_2, … x_n]$。$\theta$ 称为权重 (weights),也可以按照逻辑回归算法里的叫法,称为参数 (parameters)。$h_\theta(x)$ 称为输出 (output wires or Axon)。这个是神经网络模型中的基本运算单元。
类似逻辑回归,我们也会增加一个输入 $x_0=1$,在这里称作偏置单元 (bias unit)。
神经网络¶
神经网络可以划分成多个层,每个层有一定数量的神经元。其中第一层叫输入层,最后一层叫输出层,一个或多个中间层叫隐藏层。
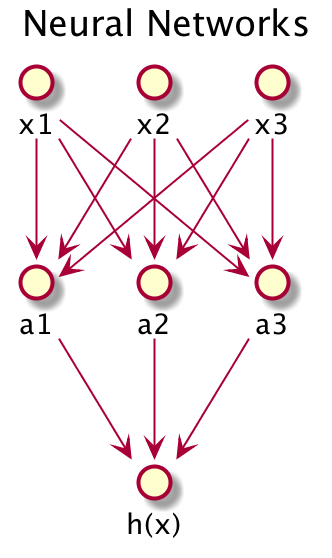
几个索引的含义
$a_i^{(j)}$: 表示第 j 层的第 i 个神经元 (unit i in layer j) $\Theta^{(j)}$: 控制神经元网络中从第 j 层转化到第 j + 1 层的权重矩阵。这个矩阵里的元素经常写成 $\Theta_{ik}^{(j)}$ 其中 j 表示第 j 层,i 表示第 j 层神经元的单元索引值,k 表示第 j 层第 i 个神经元的输入项索引值。
这段索引的描述很抽像。看一下上图的神经网络,他们的元素满足如下关系。从下面的关系中去正确地理解各个变量的索引值的含义。其中 $g(z) = \frac{1}{1 + e^{-z}}$ 就是 Sigmoid Function。
$$ a_1^{(2)} = g(\Theta_{10}^{(1)} x_0 + \Theta_{11}^{(1)} x_1 + \Theta_{12}^{(1)} x_2 + \Theta_{13}^{(1)} x_3) \\ a_2^{(2)} = g(\Theta_{20}^{(1)} x_0 + \Theta_{21}^{(1)} x_1 + \Theta_{22}^{(1)} x_2 + \Theta_{23}^{(1)} x_3) \\ a_3^{(2)} = g(\Theta_{30}^{(1)} x_0 + \Theta_{31}^{(1)} x_1 + \Theta_{32}^{(1)} x_2 + \Theta_{33}^{(1)} x_3) \\ h_\Theta(x) = a_1^{(3)} = g(\Theta_{10}^{(2)} a_0 + \Theta_{11}^{(2)} a_1 + \Theta_{12}^{(2)} a_2 + \Theta_{13}^{(2)} a_3) $$
假设 j 层有 $s_j$ 个单元,j + 1 层有 $s_{j+1}$ 个单元。那么 $\Theta^{(j)}$ 将是一个 $s_{j+1} \times (s_j + 1)$ 的矩阵。
向前传播 (Forward Propagation) 算法的向量化实现¶
针对上图的三层神经网络,其元素之前的关系按照向量化写法如下:
$$ let: z_1^{(2)} = \Theta_{10}^{(1)} x_0 + \Theta_{11}^{(1)} x_1 + \Theta_{12}^{(1)} x_2 + \Theta_{13}^{(1)} x_3 = \Theta^{(1)} x \\ \Rightarrow a_1^{(2)} = g\left( z_1^{(2)} \right) \\ a_2^{(2)} = g\left( z_2^{(2)} \right) \\ a_3^{(2)} = g\left( z_3^{(2)} \right) \\ \Rightarrow a^{(2)} = g\left( z^{(2)} \right) \\ z^{(3)} = \Theta^{(2)} a^{(2)} \\ \Rightarrow h_\Theta(x) = a^{(3)} = g\left( z^{(3)} \right) $$
上述关系的本质上,就是从第二层开始,每个神经元,都把上一层的神经元当作输入,他们之间满足逻辑回归算法。即从上一层的神经元可以计算出下一层的神经元。这也形象地称为向前传播算法。
更一般的情况,假设待训练的数据集 $X$ 是 m x n 矩阵,记作 $X \in R^{m \times n}$,其中 m 是数据集个数,n 是输入的特征数,此处假设 $X$ 里已经加入了偏置单元 (bias unit)。假设隐藏层有 s2 个单元,$\Theta^{(1)}$ 为输入层到隐藏层的转换参数。则 $\Theta^{(1)} \in R^{s2 \times n}$。输出层有 s3 个单元,$\Theta^{(2)}$ 为隐藏层到输出层的转换参数。则 $\Theta^{(2)} \in R^{s3 \times (s2 + 1)}$。我们记 $a^{(2)}$ 为隐藏层,$a^{(3)}$ 为输出层,则:
$$ a^{(2)} = g\left( X * \left( \Theta^{(1)} \right)^T \right) $$
算出后,给 $a^{(2)}$ 加上偏置单元。为了书写方便,此处我们仍然将加上偏置单元后的隐藏层记作 $a^{(2)}$。则:
$$ a^{(3)} = g\left( a^{(2)} * \left( \Theta^{(2)} \right)^T \right) $$
这几个公式就是神经网络向量化运算的重要规则。其中 $g(z) = \frac{1}{1 + e^{-z}}$ 是 Sigmoid Function。熟悉矩阵运算的同学可以验证一下上述运算在矩阵维度上的一致性。
神经网络通过学习来决定其特征
单单从 $h_\Theta(x) = g\left(\Theta^{(2)} a^{(2)}\right)$ 式子来看,神经网络的输出就是由特征 $a_1^{(2)}, a_2^{(2)}, a_3^{(2)}$ 的逻辑回归模型表述的。但这里的每个特征 $a_1^{(2)}, a_2^{(2)}, a_3^{(2)}$ 都是分别由 $x_1, x_2, x_3$ 的逻辑回归模型学习出来的。这就是神经网络的精髓所在。
神经网络的应用实例¶
运用神经网络来模拟逻辑运算¶
假设 $\Theta = [-30, 20, 20]$,
$$ h_\Theta(x) = g(\Theta^T x) = g(-30 + 20x_1 + 20x_2) $$
$g(z)$ 是 Sigmoid Function,其图形近似于 S 形。假设 $x_1, x_2 \in [0, 1]$ 是逻辑值。当 $x_1 = 0, x_2 = 0$ 时,$h_\Theta(x) = g(-30) \approx 0$。同理可以写出下面的真值表:
| x_1 | x_2 | h(x) |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 1 | 1 |
这样就模拟了逻辑 AND 的运算,即 h(x) = x1 AND x2。同理可以推算出当 $\Theta = [-10, 20, 20]$ 时,h(x) = x1 OR x2。还可以推断出当 $\Theta = [10, -20, -20]$ 时,h(x) = (NOT x1) AND (NOT x2)。当需要计算 x1 NXOR x2 时,可以用神经网络模型,即 x1 NXOR x2 = (x1 AND x2) OR ((NOT x1) AND (NOT x2))。我们把 x1, x2 当作输入,a1 = (x1 AND x2), a2 = (NOT x1) AND (NOT x2) 当作隐藏层,而最终的输出由 a1 OR a2 来计算得来了。这样我们就可以使用神经网络模拟复杂的逻辑运算。
运用神经网络来处理多类别的分类问题¶
上文介绍的神经网络只能输出 0, 1 二元问题。扩展到多个类别时,我们输出一个向量,比如针对最终结果是四种类别的问题时,输出 [1, 0, 0, 0] 表示第一种类别,输出 [0, 1, 0, 0] 表示是第二种类别,依此类推。
问:为什么不用 1, 2, 3, 4 四个不同的值来表示四种类别,而要用一个四维的向量来表示? 答:从神经网络模拟逻辑运算的例子可以看出来,一个神经元可以输出只能是从 0 到 1 的之间的值,回忆逻辑回归算法里的描述,这个值表示的是出现 0 或 1 的概率,我们可以选择一个临界点,比如 0.5。当输出值大于等于 0.5 时判定为 1,当输出值小于 0.5 时判定为 0,一个神经元不能输出整其他整数值。逻辑回归就是用来解决分类问题的离散函数,而不是对值进行预测的连续函数。针对四个类别的分类问题时,我们可以把输出层神经元个数定为 4 个,这样这四个输出层神经元的值就构成了一个有四个元素的列向量。所以,我们使用四维的列向量来表示。